Observability and Security with Service Mesh

Observability: Telemetry and Metrics
Observability: Distributed Tracing
Security: Mutual TLS
Observability: Telemetry and Metrics
In addition to service discovery and resilience, service mesh technologies can also help with app observability. Observability is being able to monitor an app’s state and to determine at a high level what’s happened when something goes wrong with the app.
Two terms that are frequently used when discussing observability are metrics and telemetry. Telemetry means the collection of data to measure something, and metrics is another name for those measures.
Engineers at Google have proposed what are called the Four Golden Signals (https://landing.google.com/sre/sre-book/chapters/monitoring-distributed-systems/). These are metrics that they think are particularly important to collect when monitoring distributed systems, which would include cloud-native apps. Here’s a brief description of the four “golden” metrics within the context of microservices and service mesh technologies:
- Latency: how long it takes to receive a reply for a request
- Traffic: how much demand the system is under, such as requests per second
- Errors: what percentage of requests result in an error
- Saturation: how close the available resources, like processing or memory, are to being fully utilized
Service mesh technologies typically support collecting most or all of the four golden metrics, and they usually support collecting additional metrics as well. Service mesh technologies also offer multiple ways to access their metrics, such as viewing them through graphical dashboards and exporting them through APIs for use in other tools.
Observability: Distributed Tracing
Another way that service meshes provide observability is through distributed tracing. The idea behind distributed tracing is to have a special trace header added to each request, with a unique ID inside each header. Typically this unique ID is a universally unique identifier (UUID) that is added at the point of Ingress. This way each ID typically relates to a user-initiated request, which can be useful when troubleshooting. Each request can be uniquely identified and its flow through the mesh monitored--where and when it traverses.
Every service mesh implements distributed tracing in different ways, but they have a few things in common. They all require the app code to be modified so each request will have the unique trace header added and propagated through the entire call chain of services. They also require the use of a separate tracing backend.
Distributed tracing is intended to be used when metrics and other information already collected by the service mesh doesn’t provide enough information to troubleshoot a problem or understand an unexpected behavior. When used, distributed tracing can provide valuable insights as to what’s happening within a service mesh.
Security: Mutual TLS
Service meshes can protect the communications between pods by using Transport Layer Security (TLS), a cryptographic protocol. TLS uses cryptography to ensure that the information being communicated can’t be monitored or altered by others. For example, if a malicious actor had access to the networks the service mesh uses, that actor wouldn’t be able to see the information being transferred in the microservice-to-microservice communications.
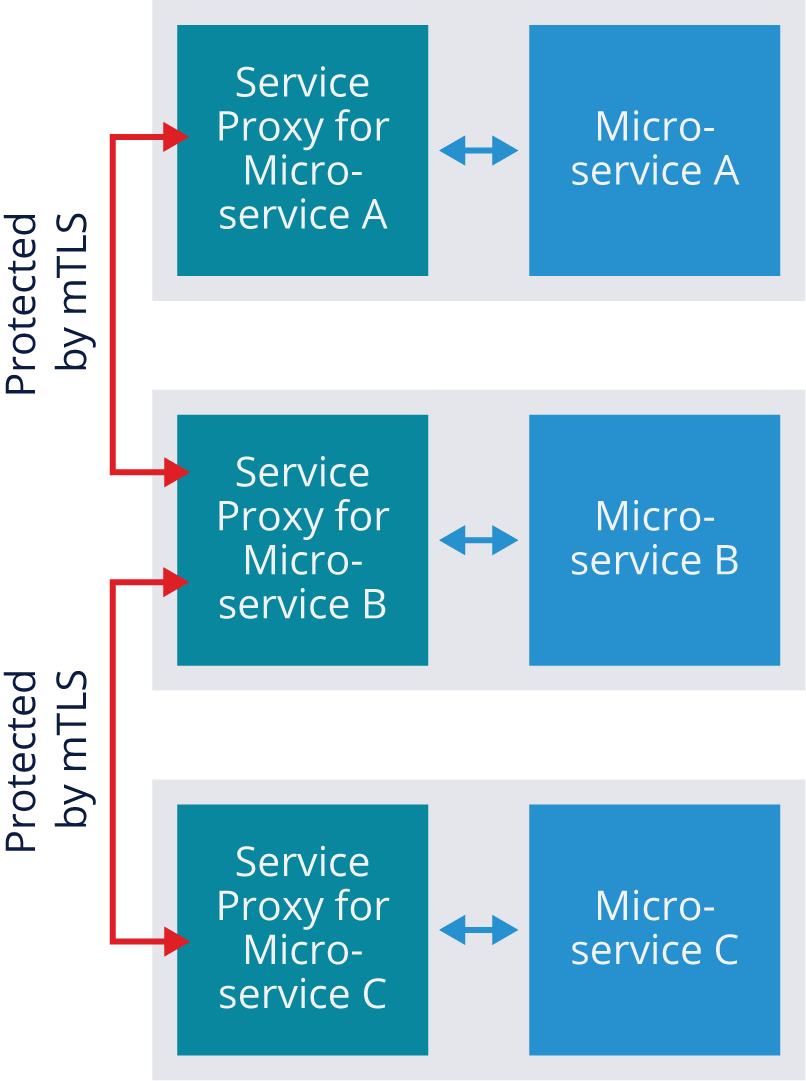
In service meshes, TLS is used between service proxies. Service meshes actually use a form of TLS called mutual TLS. Each service proxy has a secret cryptographic key that confirms its identity and allows it to decrypt the communications it receives. Each service proxy also has a certificate for every other service proxy that allows it to encrypt the communications it sends so that only the intended recipient of the communications can decrypt them.
Basically, as part of initiating any communications from pod to pod, each service proxy first verifies the identity of the other service proxy through authentication, then encrypts their communications so that no other service proxies can access it. The figure below shows a simplified example of this. One mTLS session protects the communications between the service proxies for A and B, and another mTLS session provides similar protection for communications between B and C. Because each microservice instance has a unique key, each session is encrypted in a way that only that particular microservice instance can decrypt.
It’s also important to note that mTLS only protects the communications between service proxies. It does not provide any protection for the communication within pods between a service proxy and its microservice. Service mesh architectures assume that if an attacker already has access inside the pod, there’s no point in encrypting the traffic because the attacker could access the unencrypted information regardless.
Another benefit of mutual TLS is that because it confirms the identities of each service proxy, it gives the service mesh the ability to segment the network based on those identities. Instead of the old security models that enforced policies based on IP address, new security models can enforce policies based on service proxy identity. You could create rulesets, for example, that prevent highly-trusted microservices that handle sensitive information from receiving requests from low-trusted microservices. Enforcing trust boundaries through identities verified by mutual TLS helps prevent attackers from laterally moving through microservices to reach the assets of greatest value.